hello 大家好我是Monday,今天给大家带来篇如何提取pdf中表格数据的文章。
背景:
从PDF文件中提取表格都是一个老大难的问题。无论你使用的是PyPDF2还是其他什么第三方库,提取出来的表格都会变成纯文本,效果并不好。公司之前有很多的研报pdf解析,都是通过买的第三方服务来解析的,偶然间发现
python第三方库PyMuPDF1.23.8版本 已经支持提取PDF中的表格了。还可以把表格转换为Pandas的DataFrame供你分析。让我们赶紧安装使用下吧;
PyMuPDF的使用非常简单,首先我们来安装:
1
| pip install pymupdf==1.23.0 pandas openpyxl
|
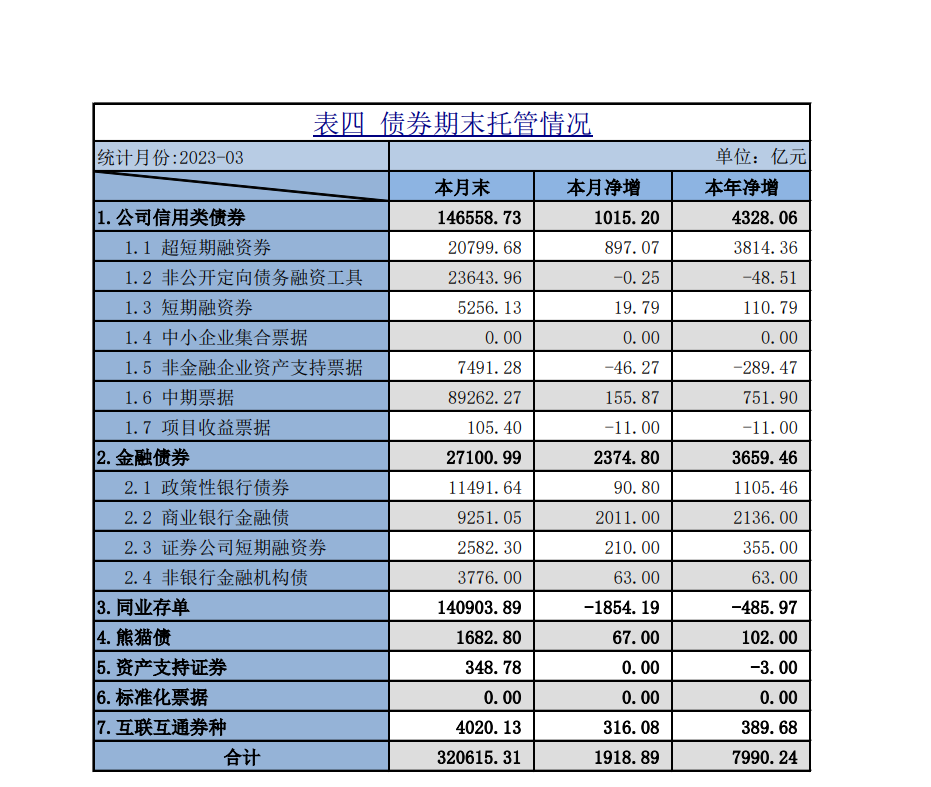
首先我们从网址上海清算所_研究与统计 (shclearing.com.cn),
https://www.shclearing.com.cn/sjtj/tjyb/ 下载债券期末托管的pdf,pdf中表格如下:
确定好解析文件后,让我们开始编写代码
1
2
3
4
5
6
7
8
| import fitz
root_path = "./表四 债券期末托管情况2023-07-31.pdf"
doc = fitz.open(root_path)
page = doc[0]
tables = page.find_tables()
df = tables[0].to_pandas()
print(df)
df.to_excel('table.xlsx', index=False)
|
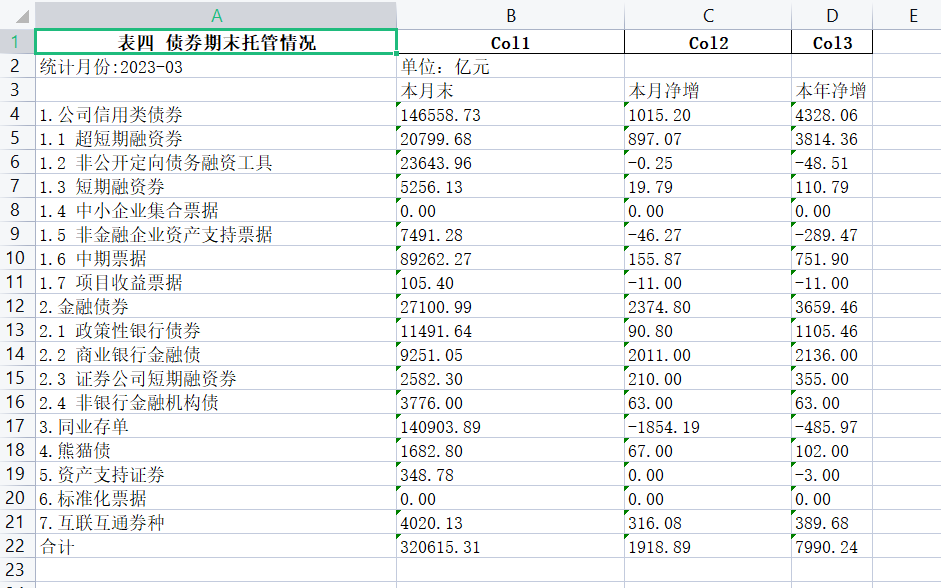
保存table.xlsx 效果如下
下面我们将解析过程中的df数据转换成json列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
df.columns = df.iloc[0]
print(df.columns.values)
if "表四 债券期末托管情况" in list(df.columns.values):
df.columns = df.iloc[2]
else:
df.columns = df.iloc[1]
df = df.iloc[2:]
keys_repalce_info = {
"本月末": "current_month_value",
"": "bond_type",
"本月净增": "current_month_end_value",
"本年净增": "current_year_value",
"上年末": "last_year_end_value"
}
keys_repalce = {}
for name in df.columns.values:
keys_repalce[name] = keys_repalce_info[name]
df.rename(columns=keys_repalce, inplace=True)
df_list = []
out_put = list(keys_repalce.values())
for i in df.index.values:
df_line = df.loc[i, out_put].to_dict()
df_line["CURRENT_MONTH_VALUE"] = df_line.get("current_month_value", "").replace(",", "")
df_line["CURRENT_MONTH_END_VALUE"] = df_line.get("current_month_end_value", "").replace(",", "")
df_line["LAST_YEAR_END_VALUE"] = df_line.get("last_year_end_value", "").replace(",", "")
df_line["CURRENT_YEAR_VALUE"] = df_line.get("current_year_value", "").replace(",", "")
df_list.append(df_line)
print(df_list)
|
结束语:
今天的分享就到这里了,欢迎大家关注微信公众号”菜鸟童靴“