hello 大家好我是Monday,本文将详细介绍如何使用Python库中的html2text模块来实现将HTML转换为Markdown的操作,并提供示例详解。
背景: 在Web开发、数据分析、网络爬虫等领域中,我们经常会遇到需要处理HTML文档的情况。但是对于需要将HTML转换为Markdown格式的需求来说,需要一些特定的工具和技术。
具体操作: 1.安装html2text模块
使用Python进行HTML到Markdown转换,首先需要安装html2text模块。可以使用以下命令进行安装:
2、我们以抓取tushare网站的接口文档为例(该网站网页使用的是Markdown)
https://tushare.pro/document/2?doc_id=158
3、正常我们直接requests请求获得的html数据
4、我们使用html2text 处理一下,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import requestsfrom lxml import etreeimport html2text as htimport redef htmlToMarkDown (html) : text_maker = ht.HTML2Text() text_maker.bypass_tables = False text = text_maker.handle(html) return text def gain_document_detail (document_url) : headers = {} response = requests.get(url=document_url, headers=headers, verify=False ) text = response.content.decode("utf-8" ) text_html = etree.HTML(text) content_etree = text_html.xpath('//div[contains(@class, "' 'content col-md")]' ) if not content_etree: return "" res = etree.tostring(content_etree[0 ], encoding="unicode" ). \ strip() text2 = htmlToMarkDown(res) return text2 document_url = f"https://tushare.pro/document/2?doc_id=158" text = gain_document_detail(document_url) res = re.search(r".*?(\*\*数据示例\*\*.*)$" , text, re.S | re.M) if res: text = text.replace(res.group(1 ), "" ) print(text)
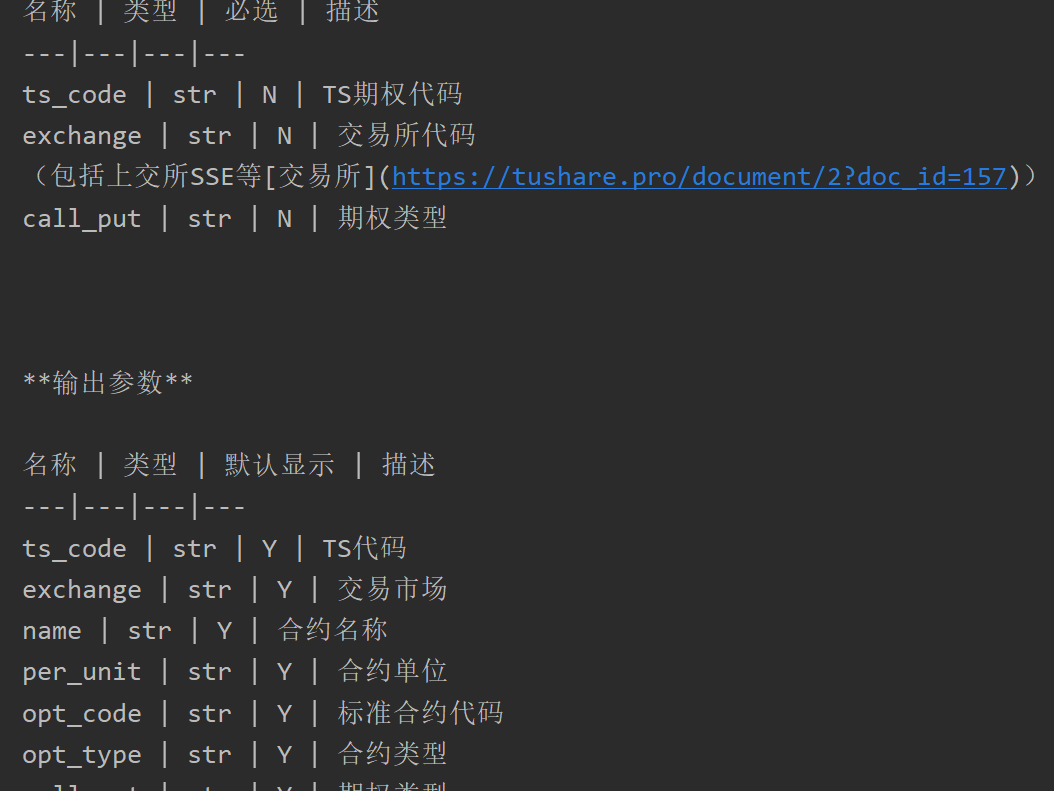
5、运行结果部门截图如下:
6、更多操作详见官网
结束语 :
今天的分享就到这里了,欢迎大家关注微信公众号”菜鸟童学 “